
求二进制数中1的个数
本文主要转载自zzd的算法-求二进制数中1的个数。 除此之外,本文还对原文中供的几种算法进行测试以及做了一定的分析。
问题描述
任意给定一个32位无符号整数n,求n的二进制表示中1的个数,比如n = 5(0101)时,返回2,n = 15(1111)时,返回4。
这也是一道比较经典的题目了,相信不少人面试的时候可能遇到过这道题吧,下面介绍了几种方法来实现这道题,相信很多人可能见过下面的算法,但我相信很少有人见到本文中所有的算法。如果您上头上有更好的算法,或者本文没有提到的算法,请不要吝惜您的代码,分享的时候,也是学习和交流的时候。
普通法
我总是习惯叫普通法,因为我实在找不到一个合适的名字来描述它,其实就是最简单的方法,有点程序基础的人都能想得到,那就是移位+计数,很简单,不多说了,直接上代码,这种方法的运算次数与输入n最高位1的位置有关,最多循环32次。
//普通法
int Fn_BitCount_Normal(unsigned n){
unsigned int c =0 ; // 计数器
while (n >0)
{
if((n &1) ==1) // 当前位是1
++c ; // 计数器加1
n >>=1 ; // 移位
}
return c ;
}一个更精简的版本如下
//普通法精简版
int Fn_BitCount_Normal_Simplify(unsigned n){
unsigned int c =0 ; // 计数器
for (c =0; n; n >>=1) // 循环移位
c += n &1 ; // 如果当前位是1,则计数器加1
return c ;
}性能测试及分析
Note: 本文函数是统计从0到0xFFFFFF所有二进制数的1的个数。
结果分别包含了算法的运行结果以及算法运行时间。
毕竟一个算法首先要求其准确性,之后才要求性能。
对普通法及其精简版进行测试结果如下
Fn_BitCount_Normal Result: 201326568, Time Consuming: 2.67302 seconds
Fn_BitCount_Normal_Simplify Result: 201326568, Time Consuming: 1.24171 seconds从结果中可以看出,精简的版本要比原版本省时一倍多。
这是因为原版相对于精简版本多了一个判断语句if((n&1)==1)。
我们可以通过汇编代码来看出两者的区别。
; 普通版
movl $0, -4(%rbp)
.L4:
cmpl $0, -20(%rbp)
je .L2
movl -20(%rbp), %eax
andl $1, %eax
testl %eax, %eax
je .L3
addl $1, -4(%rbp)
.L3:
shrl -20(%rbp)
jmp .L4
.L2:
movl -4(%rbp), %eax; 精简版
movl $0, -4(%rbp)
.L8:
cmpl $0, -20(%rbp)
je .L7
movl -20(%rbp), %eax
andl $1, %eax
addl %eax, -4(%rbp)
shrl -20(%rbp)
jmp .L8
.L7:
movl -4(%rbp), %eax从汇编中可以看出原版比精简版不仅要多一些指令,更主要的是多了一个跳转的分支。
我们知道汇编中跳转因为需要查询地址所以是比较耗时的,因此多的这个if语句导致普通版比精简版多耗时一倍多。
其实我们也可以把普通版代码去掉if语句
//普通法改进
int Fn_BitCount_Normal(unsigned n){
unsigned int c =0 ; // 计数器
while (n >0)
{
c += n&1;
n >>=1 ; // 移位
}
return c ;
}这样结果就跟精简版的结果差不多了
Fn_BitCount_Normal Result: 201326568, Time Consuming: 1.24487 seconds
Fn_BitCount_Normal_Simplify Result: 201326568, Time Consuming: 1.23572 seconds快速法
这种方法速度比较快,其运算次数与输入n的大小无关,只与n中1的个数有关。如果n的二进制表示中有k个1,那么这个方法只需要循环k次即可。其原理是不断清除n的二进制表示中最右边的1,同时累加计数器,直至n为0,代码如下
//快速法
int Fn_BitCount_Fast(unsigned n){
unsigned int c =0 ;
for (c =0; n; ++c)
{
n &= (n -1) ; // 清除最低位的1
}
return c ;
}为什么n &= (n – 1)能清除最右边的1呢?因为从二进制的角度讲,n相当于在n - 1的最低位加上1。举个例子,8(1000)= 7(0111)+ 1(0001),所以8 & 7 = (1000)&(0111)= 0(0000),清除了8最右边的1(其实就是最高位的1,因为8的二进制中只有一个1)。再比如7(0111)= 6(0110)+ 1(0001),所以7 & 6 = (0111)&(0110)= 6(0110),清除了7的二进制表示中最右边的1(也就是最低位的1)。
性能测试及分析
对快速法进行测试结果如下
Fn_BitCount_Fast Result: 201326568, Time Consuming: 0.930146 seconds快速法的速度要比普通法的速度更快,这是很正常的,因为快速法的时间复杂度跟数字里的1的个数成正比, 而普通法则跟数字的最大长度成正比。明显快速的时间复杂度要低。
查表法
动态建表
由于表示在程序运行时动态创建的,所以速度上肯定会慢一些,把这个版本放在这里,有两个原因
-
介绍填表的方法,因为这个方法的确很巧妙。
-
类型转换,这里不能使用传统的强制转换,而是先取地址再转换成对应的指针类型。也是常用的类型转换方法。
//查表法-动态建表
int Fn_BitCount_Dynamic_Table(unsigned n){
// 建表
unsigned char BitsSetTable256[256] = {0} ;
// 初始化表
for (int i =0; i <256; i++)
{
BitsSetTable256[i] = (i &1) + BitsSetTable256[i /2];
}
unsigned int c =0 ;
// 查表
unsigned char* p = (unsigned char*) &n ;
c = BitsSetTable256[p[0]] +
BitsSetTable256[p[1]] +
BitsSetTable256[p[2]] +
BitsSetTable256[p[3]];
return c ;
}先说一下填表的原理,根据奇偶性来分析,对于任意一个正整数n
-
如果它是偶数,那么n的二进制中1的个数与n/2中1的个数是相同的,比如4和2的二进制中都有一个1,6和3的二进制中都有两个1。为啥?因为n是由n/2左移一位而来,而移位并不会增加1的个数。
-
如果n是奇数,那么n的二进制中1的个数是n/2中1的个数+1,比如7的二进制中有三个1,7/2 = 3的二进制中有两个1。为啥?因为当n是奇数时,n相当于n/2左移一位再加1。
再说一下查表的原理
对于任意一个32位无符号整数,将其分割为4部分,每部分8bit,对于这四个部分分别求出1的个数,再累加起来即可。而8bit对应2^8 = 256种01组合方式,这也是为什么表的大小为256的原因。
注意类型转换的时候,先取到n的地址,然后转换为unsigned char * ,这样一个unsigned int(4 bytes)对应四个unsigned char(1 bytes),分别取出来计算即可。举个例子吧,以87654321(十六进制)为例,先写成二进制形式-8bit一组,共四组,以不同颜色区分,这四组中1的个数分别为4,4,3,2,所以一共是13个1,如下面所示。
10000111 01100101 01000011 00100001 = 4 + 4 + 3 + 2 = 13
静态表-4bit
原理和8-bit表相同,详见8-bit表的解释
//查表法-静态表-4bit
int Fn_BitCount_Static_Table_4(unsigned n){
unsigned int table[16] =
{
0, 1, 1, 2,
1, 2, 2, 3,
1, 2, 2, 3,
2, 3, 3, 4
} ;
unsigned int count =0 ;
while (n)
{
count += table[n &0xf] ;
n >>=4 ;
}
return count ;
}静态表-8bit
首先构造一个包含256个元素的表table,table[i]即i中1的个数,这里的i是[0-255]之间任意一个值。然后对于任意一个32bit无符号整数n,我们将其拆分成四个8bit,然后分别求出每个8bit中1的个数,再累加求和即可,这里用移位的方法,每次右移8位,并与0xff相与,取得最低位的8bit,累加后继续移位,如此往复,直到n为0。所以对于任意一个32位整数,需要查表4次。以十进制数2882400018为例,其对应的二进制数为10101011110011011110111100010010,对应的四次查表过程如下:红色表示当前8bit,绿色表示右移后高位补零。
第一次(n & 0xff) 10101011110011011110111100010010
第二次((n » 8) & 0xff) 00000000101010111100110111101111
第三次((n » 16) & 0xff)00000000000000001010101111001101
第四次((n » 24) & 0xff)00000000000000000000000010101011
//查表法-静态表-8Bit
int Fn_BitCount_Static_Table_8(unsigned n){
unsigned int table[256] =
{
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8,
};
return table[n &0xff] +
table[(n >>8) &0xff] +
table[(n >>16) &0xff] +
table[(n >>24) &0xff] ;
}当然也可以搞一个16bit的表,或者更极端一点32bit的表,速度将会更快。
性能测试及分析
对查表法进行测试结果如下
Fn_BitCount_Dynamic_Table Result: 201326568, Time Consuming: 15.119 seconds
Fn_BitCount_Static_Table_4 Result: 201326568, Time Consuming: 0.434318 seconds
Fn_BitCount_Static_Table_8 Result: 201326568, Time Consuming: 0.861671 seconds从中可以看出动态建表的话由于每次都需要重新建表,所以一个表被重复建立了好多次,因此耗时较长。 然而我们在实际应用中需要先建立好一个查询表,这样的话动态查询就演变成静态表。
而4-bit表本身较8-bit表小,因此需要查询计算量会增大,但结果显示4-bit表要比8-bit表耗时,这是很奇怪的。
参见stl中bitset的建表方式(Ps:stl中bitcount采用的是8-bit的查表法),发现建表的格式以unsigned char的话会节省时间以及空间。
因此对将两个版本的unsigned int改为unsigned char后结果
Fn_BitCount_Static_Table_4 Result: 201326568, Time Consuming: 0.461647 seconds
Fn_BitCount_Static_Table_8 Result: 201326568, Time Consuming: 0.473212 seconds现在的话8-bit时间要较之前少很多,然而还有问题。
8-bit建表理应速度比4-bit块,怎么耗时还比4-bit多呢。
后来经过查找,发现问题根源在于对table的初始化耗时。
每次运行bitcount时都要对table重新进行赋值,而这整个过程都是冗余的,因此将table移到函数外面如下:
//查表法-静态表-4bit
unsigned char table4[16] =
{
0, 1, 1, 2,
1, 2, 2, 3,
1, 2, 2, 3,
2, 3, 3, 4
} ;
int Fn_BitCount_Static_Table_4(unsigned n){
unsigned int count =0 ;
while (n)
{
count += table4[n &0xf] ;
n >>=4 ;
}
return count ;
}
//查表法-静态表-8Bit
unsigned char table8[256] =
{
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8,
};
int Fn_BitCount_Static_Table_8(unsigned n){
return table8[n &0xff] +
table8[(n >>8) &0xff] +
table8[(n >>16) &0xff] +
table8[(n >>24) &0xff] ;
}现在运行结果如下
Fn_BitCount_Static_Table_4 Result: 201326568, Time Consuming: 0.399976 seconds
Fn_BitCount_Static_Table_8 Result: 201326568, Time Consuming: 0.134553 seconds这样的话结果就正常了。 查表法的效率很高的,如果用32-bit的表,速度可能会更快,当然这是一种以空间换时间的做法。 具体就看需求是什么样的。
平行算法
网上都这么叫,我也这么叫吧,不过话说回来,的确有平行的意味在里面,先看代码,稍后解释
//平行计算法
int Fn_BitCount_Parallel(unsigned n){
n = (n &0x55555555) + ((n >>1) &0x55555555) ;
n = (n &0x33333333) + ((n >>2) &0x33333333) ;
n = (n &0x0f0f0f0f) + ((n >>4) &0x0f0f0f0f) ;
n = (n &0x00ff00ff) + ((n >>8) &0x00ff00ff) ;
n = (n &0x0000ffff) + ((n >>16) &0x0000ffff) ;
return n ;
}速度不一定最快,但是想法绝对巧妙。 说一下其中奥妙,其实很简单,先将n写成二进制形式,然后相邻位相加,重复这个过程,直到只剩下一位。
以217(11011001)为例,有图有真相,下面的图足以说明一切了。217的二进制表示中有5个1
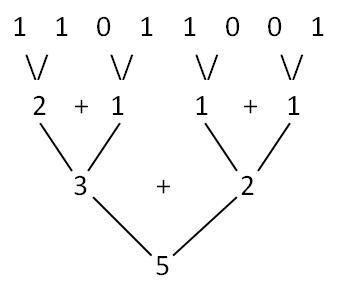
性能测试及分析
对平行算法进行测试结果如下
Fn_BitCount_Parallel Result: 201326568, Time Consuming: 0.230439 seconds并行性,速度也是很快的,整体效果要堪比查表法。 因为该版本并不需要大量的空间支持。
完美法
//完美法
int Fn_BitCount_Perfect(unsigned n){
unsigned int tmp = n - ((n >>1) &033333333333) - ((n >>2) &011111111111);
return ((tmp + (tmp >>3)) &030707070707) %63;
}最喜欢这个,代码太简洁啦,只是有个取模运算,可能速度上慢一些。区区两行代码,就能计算出1的个数,到底有何奥妙呢?为了解释的清楚一点,我尽量多说几句。
第一行代码的作用
先说明一点,以0开头的是8进制数,以0x开头的是十六进制数,上面代码中使用了三个8进制数。
将n的二进制表示写出来,然后每3bit分成一组,求出每一组中1的个数,再表示成二进制的形式。比如n = 50,其二进制表示为110010,分组后是110和010,这两组中1的个数本别是2和3。2对应010,3对应011,所以第一行代码结束后,tmp = 010011,具体是怎么实现的呢?由于每组3bit,所以这3bit对应的十进制数都能表示为2^2 * a + 2^1 * b + c的形式,也就是4a + 2b + c的形式,这里a,b,c的值为0或1,如果为0表示对应的二进制位上是0,如果为1表示对应的二进制位上是1,所以a + b + c的值也就是4a + 2b + c的二进制数中1的个数了。举个例子,十进制数6(0110)= 4 * 1 + 2 * 1 + 0,这里a = 1, b = 1, c = 0, a + b + c = 2,所以6的二进制表示中有两个1。现在的问题是,如何得到a + b + c呢?注意位运算中,右移一位相当于除2,就利用这个性质!
4a + 2b + c 右移一位等于2a + b
4a + 2b + c 右移量位等于a
然后做减法
4a + 2b + c –(2a + b) – a = a + b + c,这就是第一行代码所作的事,明白了吧。
第二行代码的作用
在第一行的基础上,将tmp中相邻的两组中1的个数累加,由于累加到过程中有些组被重复加了一次,所以要舍弃这些多加的部分,这就是&030707070707的作用,又由于最终结果可能大于63,所以要取模。
需要注意的是,经过第一行代码后,从右侧起,每相邻的3bit只有四种可能,即000, 001, 010, 011,为啥呢?因为每3bit中1的个数最多为3。所以下面的加法中不存在进位的问题,因为3 + 3 = 6,不足8,不会产生进位。
tmp + (tmp » 3)-这句就是是相邻组相加,注意会产生重复相加的部分,比如tmp = 659 = 001 010 010 011时,tmp » 3 = 000 001 010 010,相加得
001 010 010 011
000 001 010 010
-——————–
001 011 100 101
011 + 101 = 3 + 5 = 8。
注意,659只是个中间变量,这个结果不代表659这个数的二进制形式中有8个1。
注意我们想要的只是第二组和最后一组(绿色部分),而第一组和第三组(红色部分)属于重复相加的部分,要消除掉,这就是&030707070707所完成的任务(每隔三位删除三位),最后为什么还要%63呢?因为上面相当于每次计算相连的6bit中1的个数,最多是111111 = 77(八进制)= 63(十进制),所以最后要对63取模。
性能测试及分析
对完美法进行测试结果如下
Fn_BitCount_Perfect Result: 201326568, Time Consuming: 0.191481 seconds完美法效率也很高,但不知道不同编译器间是否有差别。 代码简介,效率高能,堪称完美。
位标志法
感谢网友 gussing提供
struct _byte
{
unsigned a:1;
unsigned b:1;
unsigned c:1;
unsigned d:1;
unsigned e:1;
unsigned f:1;
unsigned g:1;
unsigned h:1;
};
long get_bit_count( unsigned char b )
{
struct _byte *by = (struct _byte*)&b;
return (by->a+by->b+by->c+by->d+by->e+by->f+by->g+by->h);
}性能测试与分析
由于原文提供的代码只能计算8bit二进制数的1的数目,因此将之改为32bit的版本如下:
//位标志法
struct _byte{
unsigned a:1;
unsigned b:1;
unsigned c:1;
unsigned d:1;
unsigned e:1;
unsigned f:1;
unsigned g:1;
unsigned h:1;
};
int Fn_BitCount_BitFlags(unsigned n){
int c = 0;
unsigned char* p = (unsigned char*) &n ;
struct _byte *by[] = {(struct _byte *) &p[0],
(struct _byte *) &p[1],
(struct _byte *) &p[2],
(struct _byte *) &p[3]};
c += by[0]->a + by[0]->b + by[0]->c + by[0]->d + by[0]->e + by[0]->f + by[0]->g + by[0]->h;
c += by[1]->a + by[1]->b + by[1]->c + by[1]->d + by[1]->e + by[1]->f + by[1]->g + by[1]->h;
c += by[2]->a + by[2]->b + by[2]->c + by[2]->d + by[2]->e + by[2]->f + by[2]->g + by[2]->h;
c += by[3]->a + by[3]->b + by[3]->c + by[3]->d + by[3]->e + by[3]->f + by[3]->g + by[3]->h;
return c;
}其测试结果如下
Fn_BitCount_BitFlags Result: 201326568, Time Consuming: 0.882302 seconds一开始这个版本究竟什么意思并没有看懂。
因为原文中并没有给出解释。
后来偶然了解到struct位字段表示(bit-field)。
诸如此类定义
struct {
unsigned int is_keyword : 1;
unsigned int is_extern : 1;
unsigned int is_static : 1;
}flags;这里是定义了一个变量flags,它包含了3个1位的字段。 冒号后的数字表示的是字段的宽度(用二进制表示时的宽度)。 因此该flags变量只占3个bit。
同理,该版本中定义一个 _byte 的结构体包含8个位字段, 每个字段的长度为1。 从而该结体占8个bit。 之后只要将整数拆分成每8bit一份,就可以利用_byte轻松的访问到整数的每一个二进制位了。
想法也是比较巧妙的。
SSE4指令
感谢网友 Milo Yip提供
使用微软提供的指令,首先要确保你的CPU支持SSE4指令,用Everest和CPU-Z可以查看是否支持。
unsigned int n =127 ;
unsigned int bitCount = _mm_popcnt_u32(n) ;性能测试及分析
原文并没有给出详细的关于SSE4指令的介绍,因此特地查询了一下相关指令。
该指令的头文件<nmmintrin.h>
其中 _mm_popcnt_u32 接受的参数是32bit的整型。
int _mm_popcnt_u32 (
unsigned int a
);而_mm_popcnt_u64 接受的参数是64bit的整型。
int _mm_popcnt_u64 (
unsigned __int64 a
);测试代码如下所示:
//SSE4指令-32bit
int Fn_BitCount_SSE4_32(unsigned n){
return _mm_popcnt_u32(n);
}
//SSE4指令-64bit
int Fn_BitCount_SSE4_64(unsigned n){
return _mm_popcnt_u64(n);
}下面显示了运行结果:
Fn_BitCount_SSE4_32 Result: 201326568, Time Consuming: 0.086371 seconds
Fn_BitCount_SSE4_64 Result: 201326568, Time Consuming: 0.089418 seconds由此可见,SSE4指令的速度是最快的。 从汇编中可以看到,该函数只需要一条简单的指令
popcntl -4(%rbp), %eax ;_mm_popcnt_u32 上边是对于32bit的函数或者是下边的64bit的函数
popcntq -4(%rbp), %eax ;_mm_popcnt_u64对于指令级别的代码,速度当然是很快的,有种开了金手指的感觉。
不过需要注意的是,该指令在编译的时候需要添加-msse4.2的参数。
因为该版本对机器有所要求,所以可移植性会有所降低。
总结
这几种方法来讲,SSE4指令速度是最快的,然而其对机器的配置有所依赖,可移植性不高。
对于其他方法,还是查表法速度最快,这样是stl中bitset类型里采用的策略。
完美法跟并行法的构思很巧妙,算法精致,堪称神作。
最后,我已经把整个的测试代码上传到我的github上,地址是 https://github.com/foocoder/testbitcount
12 Feb 2016
Post by: MetaCoder