
sizeof详解
sizeof 操作符的作用是返回一个对象或类型名的长度, 返回类型是size_t,长度单位是字节。
语法
sizeof的语法主要有三种形式。
sizeof(type_name);
sizeof(expression);
sizeof expression;其中表示了获取类型变量的内存长度或获取一个具体对象的长度。最常用的方式还是前两种,最后一种方式见的比较少。
需要注意的是,sizeof本质是一个操作符,所以会有sizeof expr形式的语法,但该格式只针对于expression,不能用于类型名。
sizeof、.(成员访问符)、.*(成员指针访问运算符)、::(域运算符)以及?:(条件运算符)这5种运算符不能够被重载。
其中.和.*不能被重载是为了保证访问成员的功能不被改变,而::与sizeof则是其运算对象是类型而不是变量或一般表达式,不具备重载的特征。
使用范围
sizeof的计算一般发生在编译时,也就是说在程序编译的时候就可以计算出sizeof的大小。
所以可以将之看为常量表达式,如:
char array[sizeof(int) * 10];//Ok不过C99标准规定了sizeof也可以在运行时来计算,因此运行时的sizeof的操作也是可以正常输出的
int n;
cin>>n;//输入n=10;
char array[n];
cout<< sizeof(array);//输出10;不过据说VC6中该代码编译不通过,可能由于C99的标准没有实现的原因。
需要注意的一点是sizeof对表达式,函数返回值等进行运算的时候这些表达式函数等等并不会被调用。
int foo(){ return 0; }
int i=0;
sizeof(i++);//i=0;
sizeof(foo());//不会调用foo();C99标准规定,函数、不能确定类型的表达式以及位域(bit-field)成员不能被计算sizeof的值:
int foo(){return 0;}
void foo2(){}
sizeof(void);//error
sizeof(foo);//error
sizeof(foo());//Ok, 4
sizeof(foo2());//error
struct s{
int f1:1;
int f2:1;
int f3:1;
};
struct s s1;
sizeof(s1.f1);//error
sizeof(s1);//Ok 4用法
1. sizeof(char) = 1
在《C++ Primer》中提到,对char类型或者值为char类型的表达式进行sizeof操作保证得1。
这样从而char类型作为一个度量标准,不管编译器或者系统怎样,sizeof(char)始终为1。
2. 对引用的sizeof等于存放该引用对象的内存大小
也就是说,如果A是对B的引用的话,那么sizeof(A)将等译sizeof(B)。
但是说从内部实现的角度来看引用的话,引用应该跟指针类似,引用本身占用的空间大小应该是机器字长。
struct s{
char &c;
};
sizeof(s);//64bit 8但对引用的sizeof种种现象都显示出引用就是其本身的类型。诸如typeid,sizeof等等。
这个引用跟指针的具体区别还需要继续研究。
3. 对数组的sizeof等于对其元素的sizeof大小乘以数组的长度
char c[10] = "Hello";
char c1[] = "Hello";
int i[3] = {0};
sizeof(c);//10
sizeof(c1);//6
sizeof(i);//12需要注意的是sizeof的结果不是数组的长度,要想获得数组的长度可以用sizeof结果除以每个元素的sizeof的大小。
4. 对指针的sizeof等于存放该指针的内存大小
引用指针的区别,引用的sizeof给出的是指向的内存对象的大小,指针的sizeof给出的是指针的大小。
所以对于32bit系统而言,所有的指针的sizeof都是4,而对于64bit系统,则是8。
如果想获得指针所指的对象的内存大小,则需要解引用。sizeof(*ptr)。
这里有一道经典的题,求i1,i2的值。
void foo(char c1[3]){
int i1 = sizeof(c1);
}
void foo2(char c2[]){
int i2 = sizeof(c2);
}可能大部分都会以为i1等于3。但实际上来看,这里的i1跟i2都是指针的长度。 函数在参数传递的时候,数组已经蜕变成了指针。 也就是说下面几种函数的声明是等价的
void foo(char c[3]);
void foo2(char c[]);
void foo3(char * c);传递进去的参数都将是指针,所以sizeof的长度也是指针的长度。
5. 与strlen的区别
strlen(char*)是个求字符串实际长度的函数,返回字符串中不包括\0的长度。
char c0[10] = "Hello";
sizeof(c0);//10
strlen(c0);//5
char c1[10] = {'\0'};
sizeof(c1);//10
strlen(c1);//0
char c2[10] = "0123456789";
sizeof(c2);//10
strlen(c2);//Unkown需要注意的是最后一个例子,如果字符的长度大于等于字符数组的大小时,导致判断str终止的\0字符无法赋值进去,c2的结尾是9而不是\0,因此strlen会一直向后检索到遇到\0才停止,此时strlen的值是不可靠的。
6. Struct的内存对齐
关于struct的内存大小就会涉及到内存对齐的问题了。
举个简单的例子
struct S1{
char a;
double b;
int c;
};
sizeof(S1);乍一看我们会以为sizeof(S1) = sizeof(a)+sizeof(b)+sizeof(c),应该等于1+8+4=13。
可实际上结果却是24。这正是内存对齐的影响。
我们来看下内存对齐的几个规则:
- 对于
struct或union的各个成员,第一个成员位于偏移量为0的位置,之后的每个数据成员的偏移量都必须是min(#pragma pack(n),sizeof(data))的整数倍。 (其中#pragma pack(n)用来设置为n字节对齐,而sizeof(data)指该数据成员本身的长度) - 在数据成员完成各自的对齐之后,
struct或union本身也需要进行对齐,对齐按照min(#pragma pack(n), sizeof(maxdata))的整数倍对齐。(sizeof(maxdata)指的是数据成员中占内存最大成员的大小。) - 如果数据成员里边有复杂数据类型,诸如
struct,union或者数组之类的数据成员,这里sizeof(maxdata)会将复杂数据成员拆分成基本成员,长度还是按照基本数据成员的最长数据来算。
再来看上边那个例子,其中char a的偏移量是0,double b的偏移量应该是本身的整数倍,所以是8。最后int c的偏移量是16,满足规则。但整个struct的长度现在是16+4=20。
要满足struct对齐后是最宽的数据的整数倍,所以要在int后边填充4个字节得到24。
struct的某个成员相对于struct首地址的偏移量可以通过宏offsetof()来获取。这个宏定义在stddef.h中,如下
#define offsetof(s,m) (size_t) & (((s * )0)->m)位域(bit-field)上的内存对齐
虽然说对bit-field的成员不能够进行sizeof操作,但是我们仍然可以对bit-field的整体来进行sizeof的操作的。
bit-field的数据成员也要满足struct上的内存对齐规则。
不过特别的,bit-field还有一套自己的内存对齐规则。
- 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
- 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
- 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,Dev-C++采取压缩方式;
- 如果位域字段之间穿插着非位域字段,则不进行压缩;
- 整个结构体的总大小为最宽基本类型成员大小的整数倍。
内存对齐的作用
关于内存对齐的作用,这篇博客有着详细的说明。 然后本人就转了过来。
内存对齐的主要作用是:
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。

这是普通程序员心目中的内存印象,由一个个的字节组成,而CPU并不是这么看待的。

CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。块大小成为memory access granularity(粒度) 本人把它翻译为“内存读取粒度” 。
假设CPU要读取一个int型4字节大小的数据到寄存器中,分两种情况讨论:
- 数据从0字节开始
- 数据从1字节开始
再次假设内存读取粒度为4。
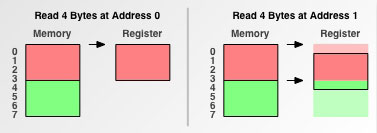
- 当该数据是从0字节开始时,很CPU只需读取内存一次即可把这4字节的数据完全读取到寄存器中。
- 当该数据是从1字节开始时,问题变的有些复杂,此时该int型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
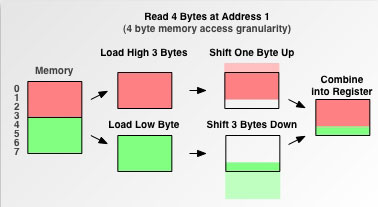
此时CPU先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分CPU肯干,其他一部分CPU遇到未对齐边界就直接罢工了。
关于pragma pack()
系统的#pragma pack(n),用来设置对齐单位的最大长度。
因为对齐的几条规则取的基本长度要求是#pragma pack()设置的和数据中最长的基本数据类型的长度取min运算。也就是说如果n设置为4的话,最大的对齐单位都不会超过4的。
例如#pragma pack(1)就是将所有的对齐按照1的整数倍来对齐,实际上就是没有进行对齐,所有数据都压缩紧凑排列。
另外该属性也可以通过__attribute__来设置的。如__attribute__((packed))即设置为紧凑模式,不进行压缩。
或者__attribut__((aligned(4)))来制定对齐的基本单位是几个字节。
struct 里长度为0的数组
理论上说长度为0的数组在标准C和C++中是不被允许的,但在GNU中这种用法却是合法的,被网上称之为柔性数组。
struct s{
int length;
char c[0];
};
sizeof(s);//4可以看到柔性数组并不占用空间。 它的最典型的用法就是位于数组中的最后一项,如上面所示,这样做主要是为了方便内存缓冲区的管理。 如果你将上面的长度为的数组换为指针,那么在分配内存时,需采用两步:首先,需为结构体分配一块内存空间;其次再为结构体中的成员变量分配内存空间。 这样两次分配的内存是不连续的,需要分别对其进行管理。 当使用长度为的数组时,则是采用一次分配的原则,一次性将所需的内存全部分配给它。 相反,释放时也是一样的。
参考资料
- 《C++ Primer》
- 百度百科
- 内存对齐的规则以及作用
- 浅析长度为0的数组
06 Mar 2016
Post by: MetaCoder